上周在一个 AI 规划会里,业务负责人开场就问:“我们要不要先把 Agent Framework 定下来?”
我当时没有直接回答框架,而是先问了另一个问题:你们现在有没有一套稳定、跨部门可复用的数据对象定义?
会议室安静了几秒。这个停顿本身,就是今天很多企业级 AI 项目的真实起点。
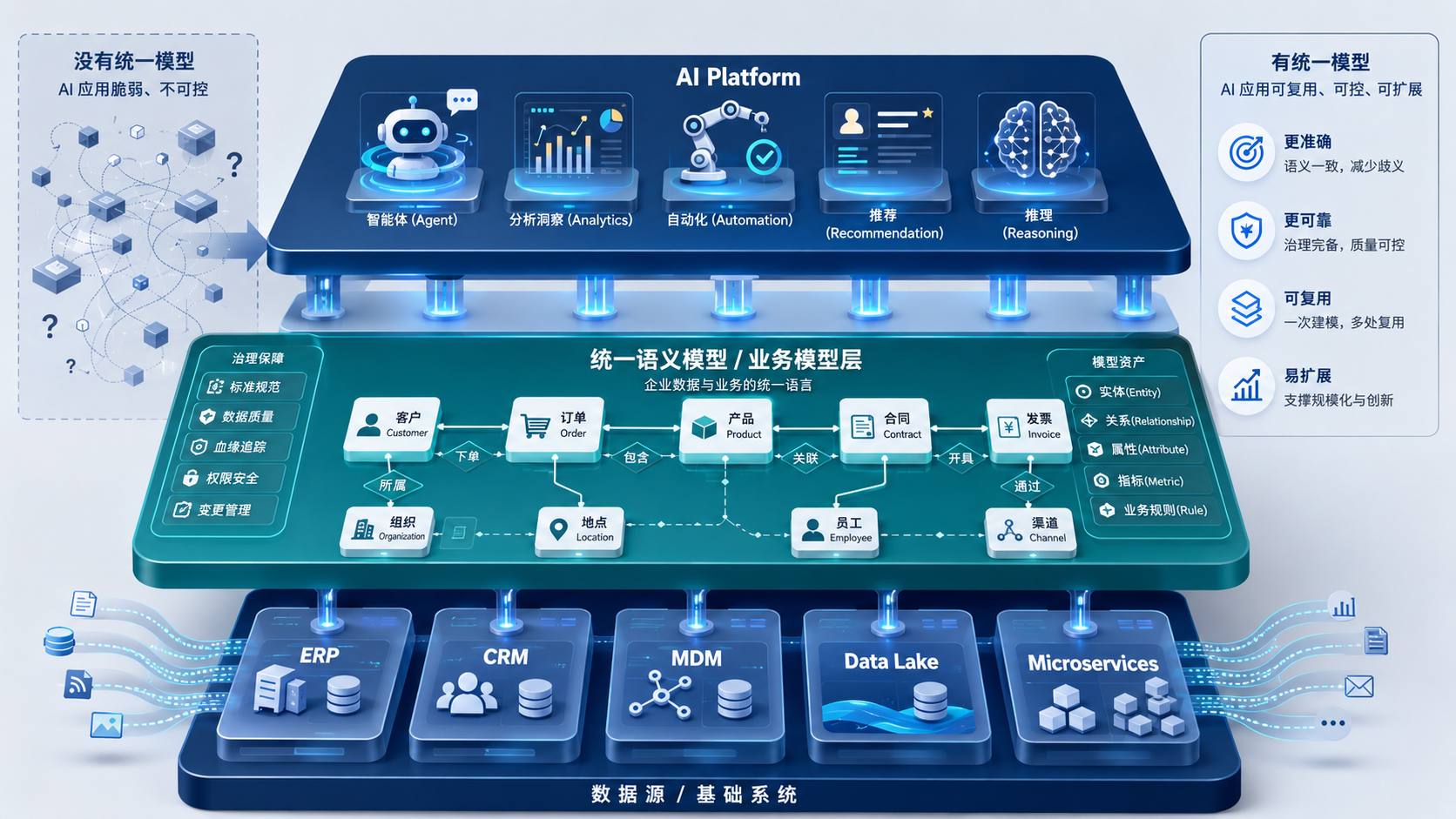
过去三十年的建设主线,其实一直在“建模”
如果把企业信息系统建设拉成一条时间线,会看到三段非常典型的演进:
ERP / CRM / ESB / MDM阶段:先把关键交易流程和主数据管起来。微服务 / 数字中台 / 大数据 / 数据湖阶段:再把能力拆分、数据汇聚、分析提速。AI Platform阶段:开始追求基于语义理解和自动化决策的系统能力。
表面上看,每一代技术栈都不一样;但从方法论看,它们都在做同一件事:把企业的核心资产和业务流程,变成可被系统理解与执行的模型。
所以,今天讨论 AI,不是突然出现了一项全新的基础工作,而是那项“早就该做但一直没做完”的工作,被再次推到了台前。
为什么这件事一直推进慢
在很多企业里,数据与业务建模从来不是没人知道它重要,而是很难被持续投入。过去项目里,这件事常常被排在路线图后段,原因也很现实:
- 成本高:建模是跨系统、跨部门、跨口径的“硬活”,不是一两次接口联调就能结束。
- 协同难:财务、供应链、营销、研发对同一个对象的定义经常不一致。
- 回报慢:在传统 IT 体系下,建模收益往往以“长期质量提升”体现,短期难以量化。
于是,多数企业都做成了“局部最优”:某个域里做得不错,但缺少全局统一的对象语义和关系约束。一旦系统要横向协同,就又回到口径对齐和临时映射。
企业级 AI 改变了成本收益结构
这次不一样的地方在于,AI 的消费方式直接暴露了建模缺口。
过去 BI 报表还能靠人工兜底口径;现在 AI 要做跨流程问答、推理、推荐和执行,系统必须先知道“谁是谁、谁和谁是什么关系、动作在哪些边界内可执行”。如果没有稳定模型,AI 只能在不稳定数据上生成不稳定结论。
换句话说,AI 不是贴在旧系统上的“能力外挂”。
它反向倒逼企业重新定义数据与业务的表达方式,并且这次的回报路径非常直接:
- 模型一致,AI 才能复用;
- 语义清晰,AI 才能可控;
- 关系可计算,AI 才能扩展。
因此,数据与业务建模正在从“长期优化项”,转成企业级 AI 的“前置必要条件”。
最近项目里的三个误区
这半年看了几类 AI 落地项目,真正卡住进度的,通常不是大家一开始最担心的点。
第一个误区是把重心放在 Agent Framework 选型。
团队花很多时间比较编排能力、插件机制、状态管理,结果上线后发现最难的是“同一个客户对象在三个系统里含义不同”。
第二个误区是把问题归因于模型能力。
当回答不稳定时,第一反应是换更强模型、加更长上下文,但根因往往是底层数据定义本身不稳定,模型只能放大这种不稳定。
第三个误区是高估了“临时数据胶水”的可持续性。
项目早期用几层映射脚本可以跑通 Demo,但一到跨部门、跨场景复用,就会迅速退化成维护负担。
所以,企业级 AI 的主矛盾,很多时候不是“有没有最先进的框架和模型”,而是“有没有可以被 AI Platform 稳定消费的数据与业务模型”。
一个更可落地的推进顺序
从咨询实践看,比较稳的路径不是先追求大而全,而是先建立最小可复用建模单元,再逐步扩展:
- 先定义核心对象(客户、合同、订单、产品、项目等)的统一语义。
- 再定义对象关系和关键动作(审批、变更、履约、结算等)的边界。
- 最后让 AI 应用去消费这套对象-关系-动作模型,而不是直接消费原始表结构。
这套顺序的好处是,技术建设和业务价值可以同步验证。每落一个对象域,都会直接改善 AI 的可解释性和可复用性,而不是把价值推迟到“平台全部建完以后”。
结语:先把地基做成“可计算的业务”
“先做数据建模,再谈 AI”并不是保守,而是更务实的加速策略。
企业今天真正需要的,不只是一个能跑通演示的 AI 应用,而是一套可长期演化的 AI 能力底座。这个底座的核心,不在某个单一框架,也不在某个单一模型,而在于企业是否把自己的核心资产与流程,表达成了统一、清晰、可计算的业务模型。
这件事并不新,但现在终于有了足够强的外部驱动力和足够清晰的回报路径。也正因此,它值得被放回企业级 AI 建设的第一优先级。