EDA, Event-Driven Architecture, is “a software architecture paradigm promoting the production, detection, consumption of, and reaction to events” (from Wikipedia). It is not new at all. Like many technology concepts, there are few movements, methodologies, tools that appeared behind EDA, direct or indirect related to EDA, as “Figure 1, Things behind Event-Driven Architecture”.
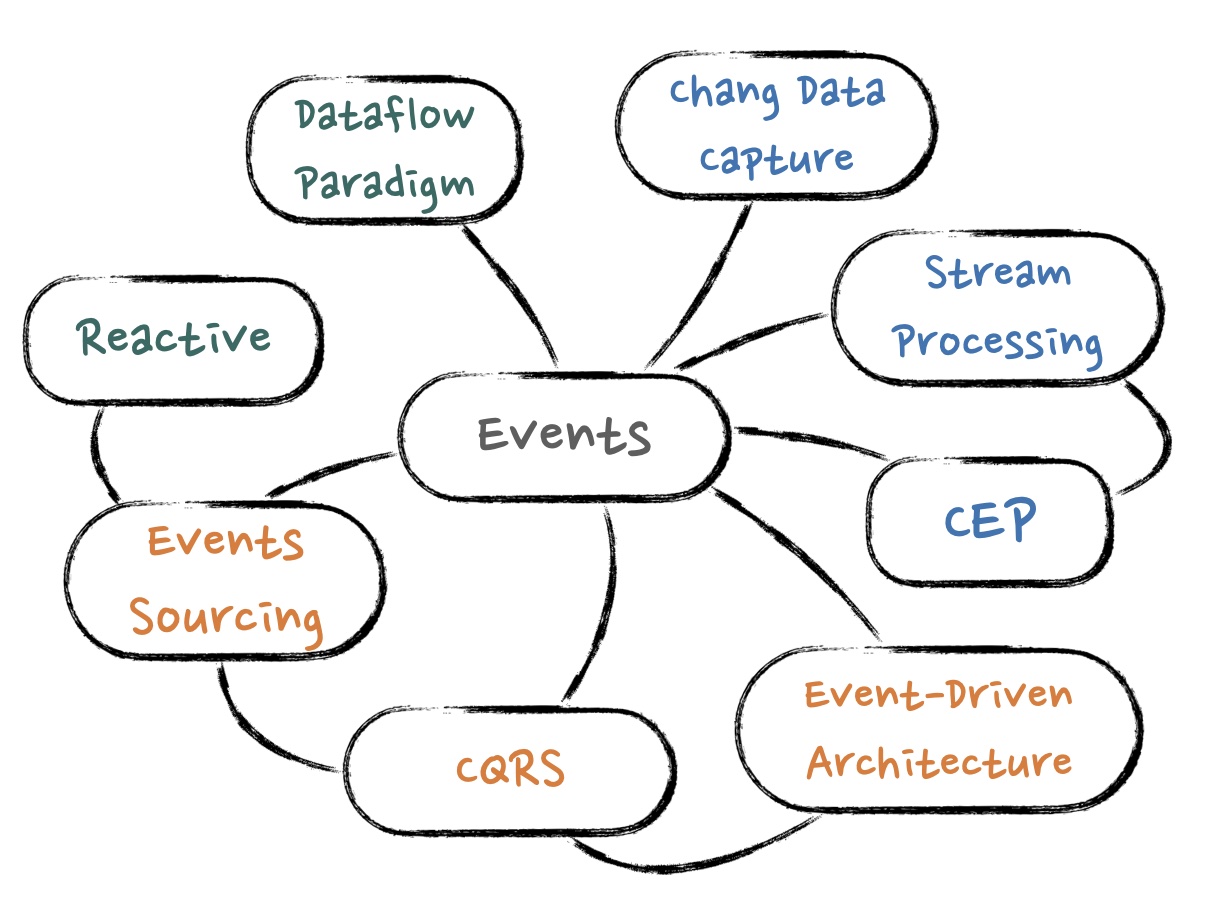 Figure 1, Things behind Event-Driven Architecture
Figure 1, Things behind Event-Driven Architecture
In the Enterprise IT area, DDD influences how people think, design and implement software. The concepts such as Event Sourcing, CQRS, SAGA from the DDD community are used to handle complex domain logic and business logic. In contrast, such as Stream Processing and CEP are from Internet companies with a much larger dataset. In the lower level, programming languages also evolved to support event- and async-based paradigm (reactive, dataflow). There are many languages and libraries like Elixir, Oz, Akka, Erlang OTP etc.
What is interesting here is that almost all things have a common aspect: they are both related to “events”!
Like any buzzwords in IT, such as Microservices, DevOps, Agile, it is better to clarify what it means to an organization before implementing it. So in the rest of this article, it will be explained what EDA is for us. As “Figure 1, Things behind Event-Driven Architecture” implies, let’s start from “Events”. 1, Things behind Event-Driven Architecture” implies, let’s start from “Events”.
Events! Event can have two hats
This is the very basis of EDA - event is the first citizen. Generally, programs communicate with others by events, instead of normal synchronized calls.
Exchanging events can decouple systems from runtime dependencies, improve availability in case of system failure. On the other hand, events manner causes the system behaviour to get more indeterminate. This makes troubleshooting difficult, and most developers are not familiar with this paradigm.
Although there are pros and cons to events, events are getting more popular. Nowadays, event can have two hats
- capturing and noticing things just happened, such as “order #123 done. send email to buyer.”
- carrying data of state transfer, such as “order #123 updated price to 20$.”
The first type of event is independent of each other. Says it needs to send 3 confirmation emails to 3 consumers, it doesn’t matter the sequence of sending activities.
In comparison with the first, the second type of event is generally ordered strictly. For example, if an order’s price is updated twice, from 15$ to 20$, then to 22$, then there are two events with updated prices. So the events must be received in the same order as they were sent. Then, the order’s final price stays at 22$ in events consuming systems.
The ordered events take a critical role in modern event-based systems.
To capture all changes of all states (Event Sourcing)
Image how it will proceed for the previous order example. All changes of a single order, such as creating order, modifying order data (e.g. address, price, items), closing order, cancelling order etc., are valuable assets that are worth considering seriously.
If all changes of states of an application are captured and persisted as a sequence of events, then these events could be replayed to recovery the state of the application. In other words, “events” is the single source of truth. This is exactly what Event Sourcing does.
Event Sourcing works with application state is very similar to what Github works with source code. All the historical activities can be retrieved. You can not only query what your application looks like now, but also how it got there.
Generally, Event Sourcing is a fundamental architectural decision - to capture change events of all states or none state. Events can contain specific domain knowledge, but the store of events must be generic. Just like Github treats all source code files as plain text format, without knowing the syntax of programming languages.
Event Sourcing does provide the decoupling of “things happened” and “things are recorded”. In many cases, this separation improves availability and better throughput capacity. However, there are also drawbacks to applying Event Sourcing, includes,
- Difficult to understand. To wrap a state change into a domain event is not a natural way of thinking for most people.
- Side-effect to external systems. Although replaying events can rebuild the system, it doesn’t help to recovery the impaction for external systems, for example, if an event triggers sending email, then simply replay the event cannot revoke the email.
- Transaction. No out-of-box transaction mechanism that can guarantee the data follows some restrictions. When you send an “update username” event, you cannot make sure the new username is not duplicated with existing ones.
Events for writing, Database/Cache/Search for reading (CQRS)
In the last section when we discuss the benefit of Event Sourcing, I only said “decoupling”. Seems not very convincing to people. Because Event Sourcing is only the first part of the story. Event Sourcing is the optimization of “changing” or “writing” data.
However, “reading” data is the second part of the story.
One of the biggest benefits of Event Sourcing is it allows the applications to have different models for “writing” and “reading” data. And for sure, it needs “CQRS” to complete the whole story. This approach of dealing with data is different from the traditional CRUD means. With the latter, all data operations go to a single model - a relational normalised model.
Nowadays, there are increasing cases that a single model hardly handles the optimization both for reading and writing data, especially people are expecting more ways for reading data - RDBM for consistent records, search engine for free format queries, cache for fast responses.
Therefore, the notion of CQRS was introduced naturally here. Since “writing” and “reading” cannot share one model, then having separated models for different purposes seems to be a good solution … in theory. In practice, using this approach will encounter some complicities from design, code and infrastructure aspects.
So it is time to …
Bring together, Event Sourcing, CQRS and Stream Processing
The last section describes a common challenge of enterprise IT - as long as the business is growing and changing, data is stored and consumed for different purposes. Imagine you start the building system with a web app and a database. Then database is getting slow, and you add a cache. Then customer wants to query with free text, and you add s search engine. Then search engine is getting slow, and you add a cache for search …
As “Figure 2, Data stores in forms” shows:
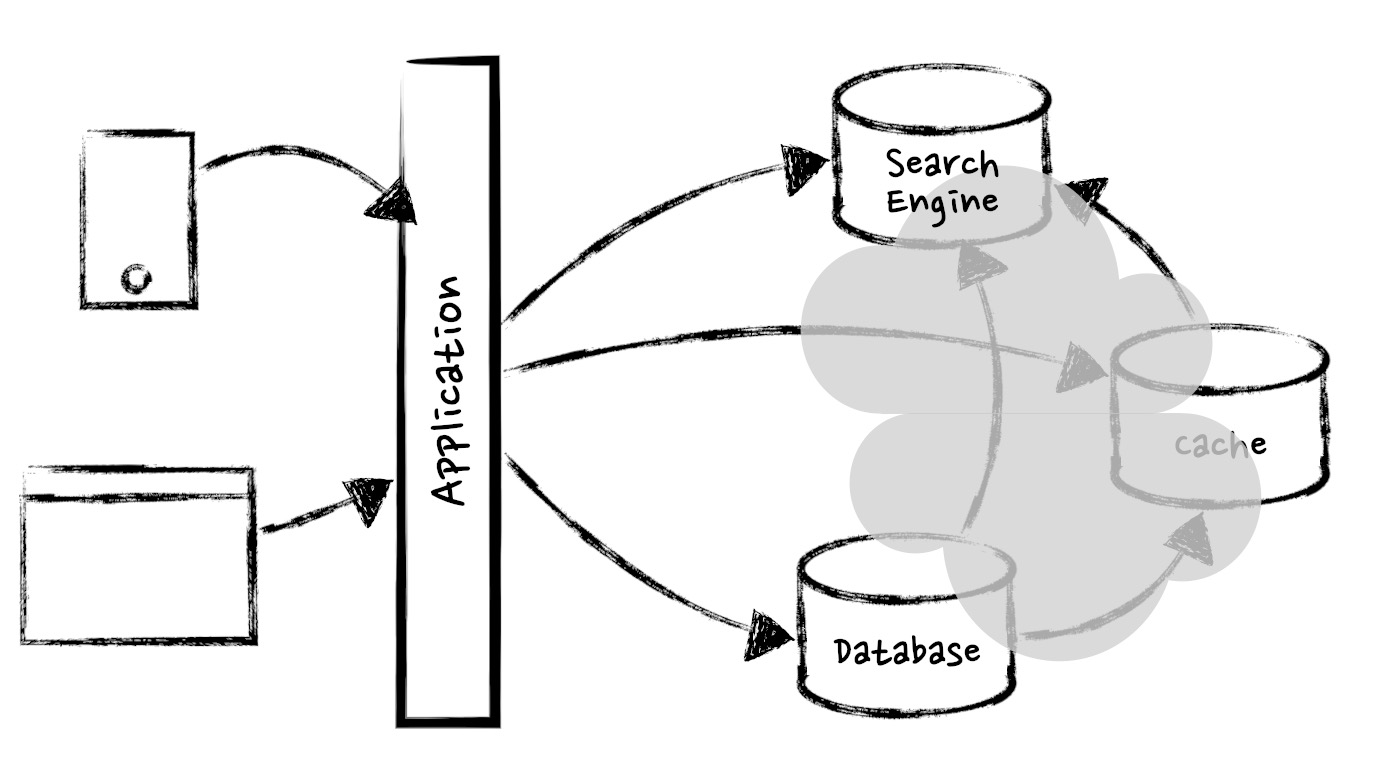 Figure 2, Data stores in forms
Figure 2, Data stores in forms
The real trouble here is that many of them end up containing the same data, or related data, but in different forms. Whenever a piece of data changes in one place, it needs to change correspondingly in all the other places where there is a copy or derivative of that data. There are few methods for solving the problem. The most remarkable one might be “Distributed Transaction”, with lots of varieties and protocols, like 2PC, Dual Write, TCC, XA etc. However, these ideas were bright 30 years ago, and are error-prone in current IT.
Events as single source of truth
Textbooks in the past few decades educate people that database is the source of truth. Now it is time to throw them away!
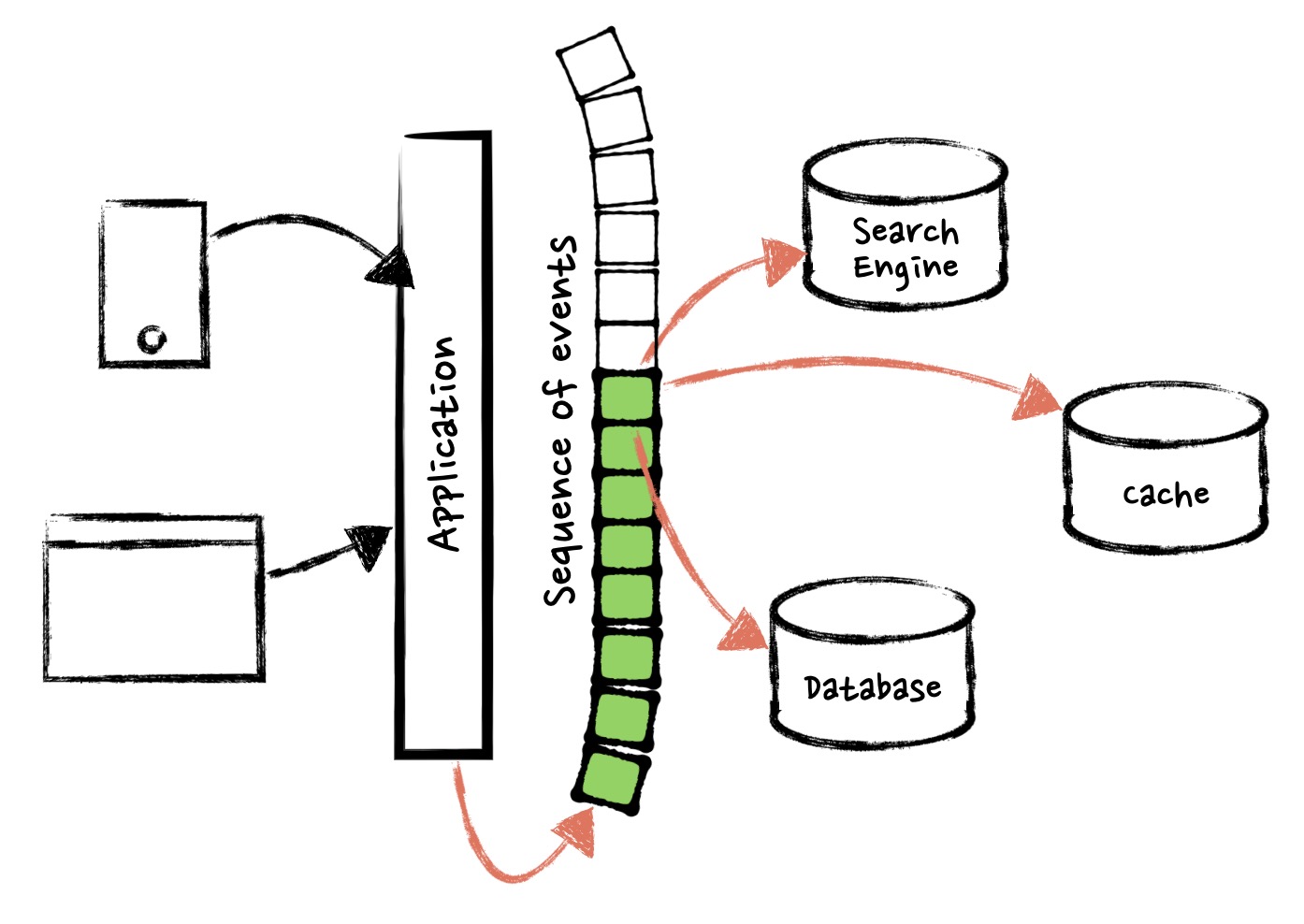 Figure 3, Sequence of Events as Single Source of Truths
Figure 3, Sequence of Events as Single Source of Truths
Assuming we’ve already implemented Event Sourcing / CQRS as DDD recommended, every state change is respected as an event. We can combine with another tool called “Stream Processing” from the world with big data. As “Figure 3, Sequence of Events as Single Source of Truth” shows, the solution is to use the sequence of events as single source of truth, and database is a snapshot, cache is a snapshot, search index is a snapshot, etc.
The idea is extremely straightforward. All data changes are written to “events”, an immutable, ordered sequence of truth, and are distributed into distinguished snapshots (e.g. RDBM, Search Engine, Cache, Graph Processor, DWH etc).
Here, I quote the definition of “the sequence of events” from this article authored by Jay Kreps, “is perhaps the simplest possible storage abstraction. It is an append-only, totally ordered sequence of records ordered by time”.
Events, as the optimized model for writing, is responsible for handling writing. Snapshots are specific reading models for different purposes. If any snapshot crashed, it can be recovered via replay of all events.
The fundamental of this approach is the “Stream Processing” capability. It looks like a traditional message broker but with some essential differences - it must manner as a container of event logs but not job queues.
Measure EDA?
Like any other IT buzzword, “Event-Driven Architecture” is very imprecise. This article depicts four forms of implementing EDA, from simple to complicated,
- Use Events as commands and notifications
- Event Sourcing
- CQRS
- Stream Processing
When an enterprise adopts EDA, this could be an approach to measure the maturity of implementation.
References
The Log: What every software engineer should know about real-time data’s unifying abstraction Introducing Kafka Streams: Stream Processing Made Simple Distributed Snapshots: Determining Global States of Distributed Systems CQRS from Martin Fowler Turning the database inside out with Apache Samza Making sense of stream processing